Bike share Analysis
In this project, we will analyze the data from a bike sharing service and identify the usage patterns depending on time features and weather conditions.
The goal is to reduce the gap between theoritical knoweledge and pratical experience by applying concepts such as data understanding, data cleaning, visual analysis,hypothesis testing and time series to the available dataset.
The dataset used can be found here: https://bit.ly/47ttIDJ
Contents:
Introduction:
Bike sharing stands as a foundational service within the urban mobility landscape. Its accessibility without the need for a driving license, cost-effectiveness compared to traditional car-sharing services due to lower maintenance and insurance expenses, and the swiftness it offers for city commuting make it highly attractive. Consequently, comprehending the pivotal factors that drive bike sharing requests holds significant importance for both companies providing these services and the users who rely on them.
1. Understanding the Data:
| instant | dteday | season | yr | mnth | hr | holiday | weekday | workingday | weathersit | temp | atemp | hum | windspeed | casual | registered | cnt | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2011-01-01 | 1 | 0 | 1 | 0 | 0 | 6 | 0 | 1 | 0.24 | 0.2879 | 0.81 | 0.0 | 3 | 13 | 16 |
| 1 | 2 | 2011-01-01 | 1 | 0 | 1 | 1 | 0 | 6 | 0 | 1 | 0.22 | 0.2727 | 0.80 | 0.0 | 8 | 32 | 40 |
| 2 | 3 | 2011-01-01 | 1 | 0 | 1 | 2 | 0 | 6 | 0 | 1 | 0.22 | 0.2727 | 0.80 | 0.0 | 5 | 27 | 32 |
| 3 | 4 | 2011-01-01 | 1 | 0 | 1 | 3 | 0 | 6 | 0 | 1 | 0.24 | 0.2879 | 0.75 | 0.0 | 3 | 10 | 13 |
| 4 | 5 | 2011-01-01 | 1 | 0 | 1 | 4 | 0 | 6 | 0 | 1 | 0.24 | 0.2879 | 0.75 | 0.0 | 0 | 1 | 1 |
According to the description of the original data, provided in the Readme.txt file (data folder), we can split the columns into three main groups:
• Temporal features: This contains information about the time at which the record was registered. This group contains the dteday, season, yr, mnth, hr, holiday, weekday, and workingday columns.
• Weather related features: This contains information about the weather conditions. The weathersit, temp, atemp, hum, and windspeed columns are included in this group.
• Record related features: This contains information about the number of records for the specific hour and date. This group includes the casual, registered, and cnt columns.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 17379 entries, 0 to 17378
Data columns (total 17 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 instant 17379 non-null int64
1 dteday 17379 non-null object
2 season 17379 non-null int64
3 yr 17379 non-null int64
4 mnth 17379 non-null int64
5 hr 17379 non-null int64
6 holiday 17379 non-null int64
7 weekday 17379 non-null int64
8 workingday 17379 non-null int64
9 weathersit 17379 non-null int64
10 temp 17379 non-null float64
11 atemp 17379 non-null float64
12 hum 17379 non-null float64
13 windspeed 17379 non-null float64
14 casual 17379 non-null int64
15 registered 17379 non-null int64
16 cnt 17379 non-null int64
dtypes: float64(4), int64(12), object(1)
memory usage: 2.3+ MB
We can observe that the dataset has 17379 records and 17 columns. There are no missing values. We can also see that the dteday column is an object data type, we will need to change it to datetime so that we can for with time series.
| instant | season | yr | mnth | hr | holiday | weekday | workingday | weathersit | temp | atemp | hum | windspeed | casual | registered | cnt | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 17379.0000 | 17379.000000 | 17379.000000 | 17379.000000 | 17379.000000 | 17379.000000 | 17379.000000 | 17379.000000 | 17379.000000 | 17379.000000 | 17379.000000 | 17379.000000 | 17379.000000 | 17379.000000 | 17379.000000 | 17379.000000 |
| mean | 8690.0000 | 2.501640 | 0.502561 | 6.537775 | 11.546752 | 0.028770 | 3.003683 | 0.682721 | 1.425283 | 0.496987 | 0.475775 | 0.627229 | 0.190098 | 35.676218 | 153.786869 | 189.463088 |
| std | 5017.0295 | 1.106918 | 0.500008 | 3.438776 | 6.914405 | 0.167165 | 2.005771 | 0.465431 | 0.639357 | 0.192556 | 0.171850 | 0.192930 | 0.122340 | 49.305030 | 151.357286 | 181.387599 |
| min | 1.0000 | 1.000000 | 0.000000 | 1.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1.000000 | 0.020000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1.000000 |
| 25% | 4345.5000 | 2.000000 | 0.000000 | 4.000000 | 6.000000 | 0.000000 | 1.000000 | 0.000000 | 1.000000 | 0.340000 | 0.333300 | 0.480000 | 0.104500 | 4.000000 | 34.000000 | 40.000000 |
| 50% | 8690.0000 | 3.000000 | 1.000000 | 7.000000 | 12.000000 | 0.000000 | 3.000000 | 1.000000 | 1.000000 | 0.500000 | 0.484800 | 0.630000 | 0.194000 | 17.000000 | 115.000000 | 142.000000 |
| 75% | 13034.5000 | 3.000000 | 1.000000 | 10.000000 | 18.000000 | 0.000000 | 5.000000 | 1.000000 | 2.000000 | 0.660000 | 0.621200 | 0.780000 | 0.253700 | 48.000000 | 220.000000 | 281.000000 |
| max | 17379.0000 | 4.000000 | 1.000000 | 12.000000 | 23.000000 | 1.000000 | 6.000000 | 1.000000 | 4.000000 | 1.000000 | 1.000000 | 1.000000 | 0.850700 | 367.000000 | 886.000000 | 977.000000 |
We can say that the maximum casual hourly ride is 367 while it is 887 for the registered rides.
2. Data Preprocessing
In this section, we perform data cleaning, transformation and scaling.
Transform seasons
| |
Transform yr
| |
Transform weekday
| |
Transform weathersit
| |
Transform humidity (hum) and wind speed
| |
| |
| season | yr | weekday | weathersit | hum | windspeed | |
|---|---|---|---|---|---|---|
| 0 | winter | 2011 | Saturday | clear | 81.0 | 0.0 |
| 1 | winter | 2011 | Saturday | clear | 80.0 | 0.0 |
| 2 | winter | 2011 | Saturday | clear | 80.0 | 0.0 |
| 3 | winter | 2011 | Saturday | clear | 75.0 | 0.0 |
| 4 | winter | 2011 | Saturday | clear | 75.0 | 0.0 |
3. Exploratory Data Analysis
Univariate analysis
We begin our analysis of the single features by focusing on the two main ones:
- registered: The number of rides performed by registered users
- casual: The number of rides performed by non-registered ones.
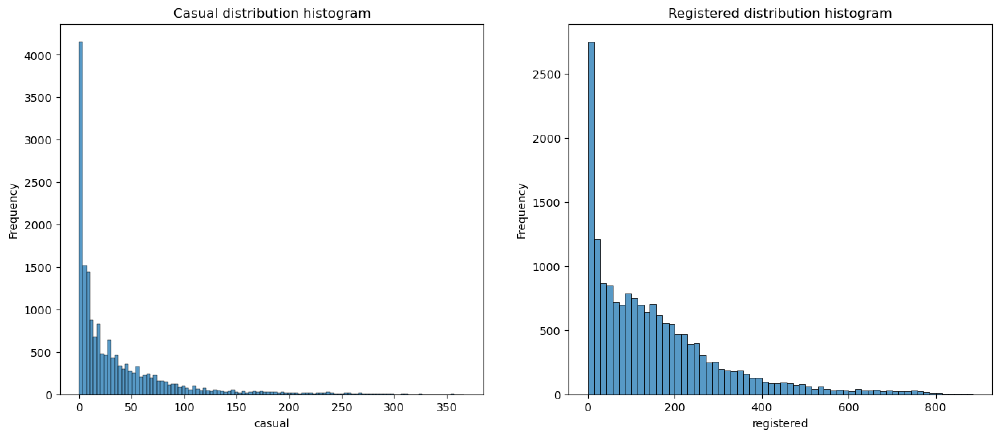
We can say from the charts, both distributions are right-skewed.
Registered versus Casual Use Analysis
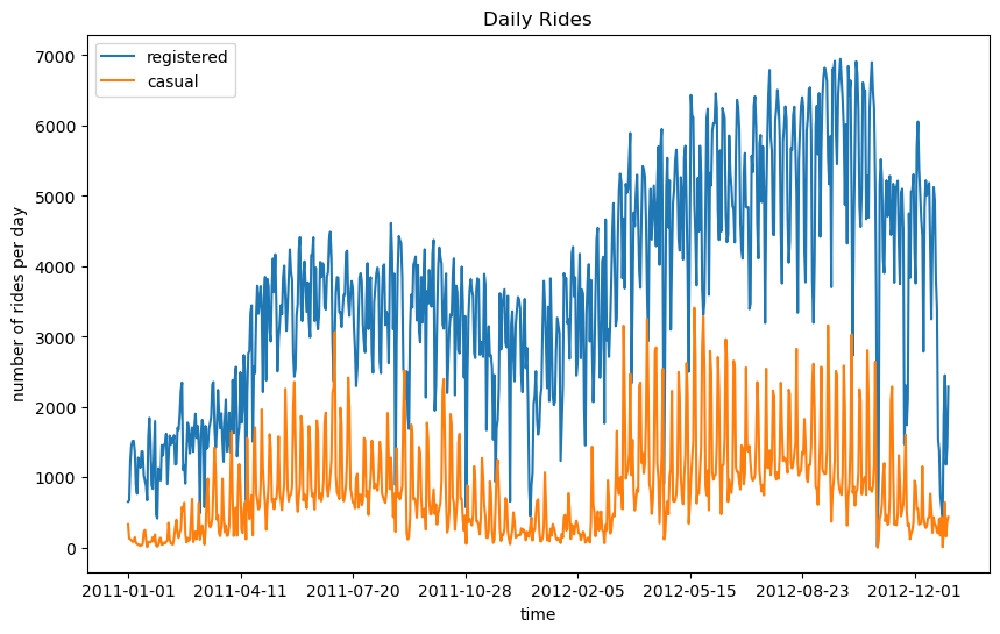
We can see from the above figure that the number of registered rides is always above and significantly higher than the number of casual rides per day. Furthermore, we can observe that during winter, the overall number of rides decreases (which is totally in line with our expectations, as bad weather and low temperatures have a negative impact on ride sharing services).
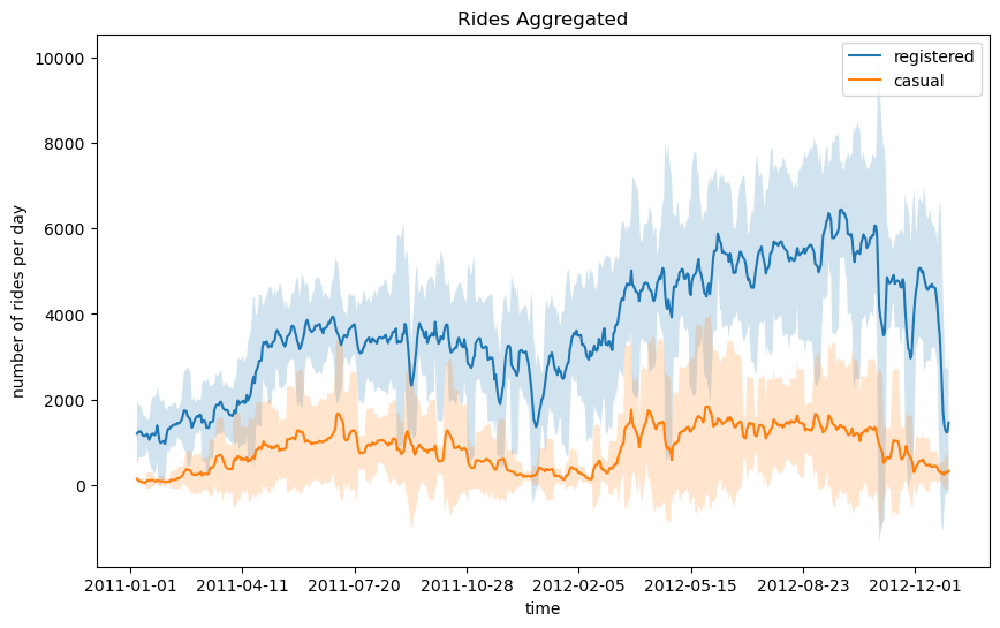
We can notice that there is quite a lot of variance in the time series of the rides in the above figure. One way to smooth out the curves is to take the rolling mean and standard deviation of the two time series and plot those instead. In this way, we can visualize not only the average number of rides for a specific time period (also known as a window) but also the expected deviation from the mean
Distributions of requests over separate hours and days of the week
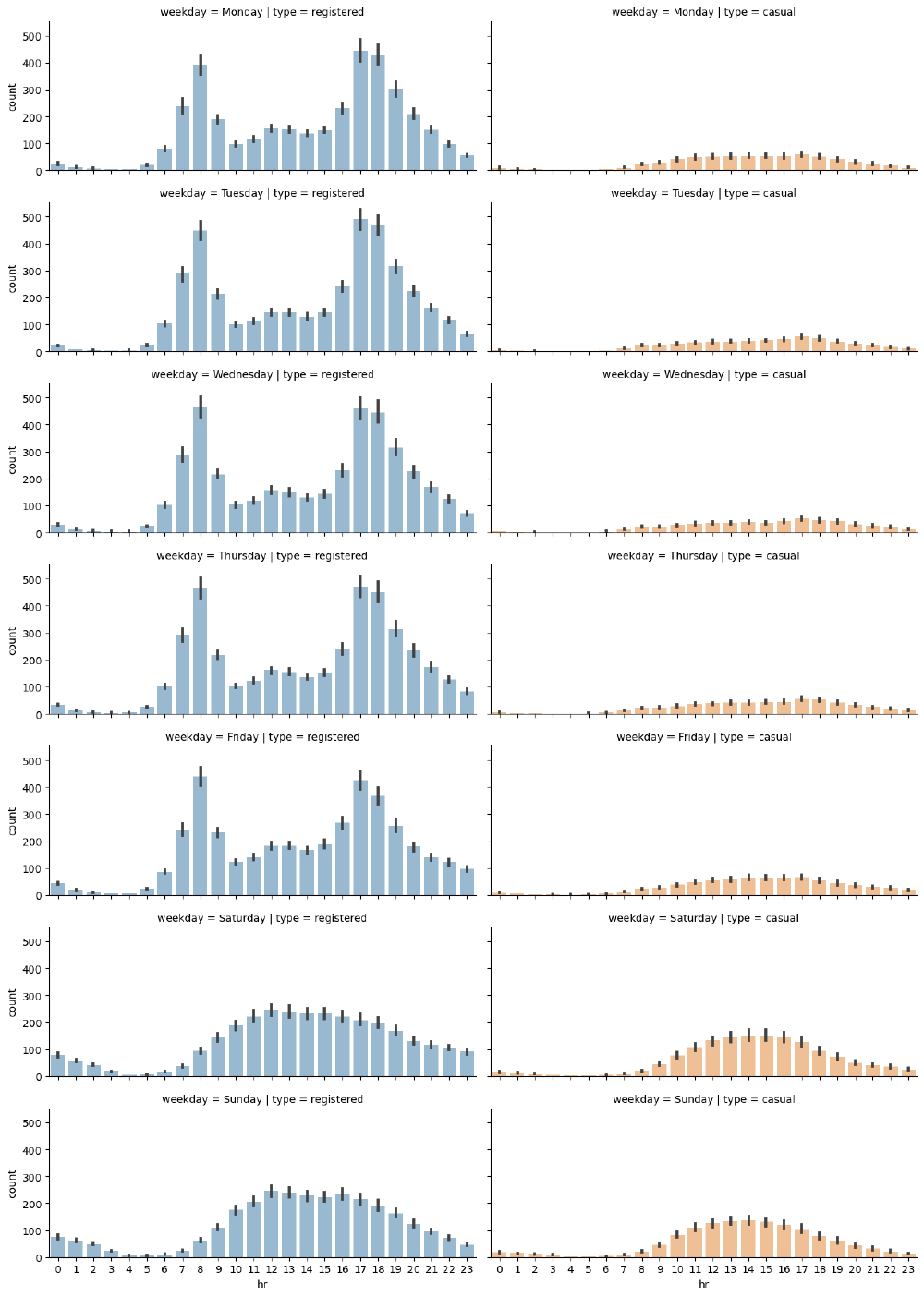
We can immediately note that on working days, the highest number of rides for registered users takes place around 8 AM and at 6 PM, with more rides for registered users. The distribution for registered users is nearly bimodal with the modes being 8 AM and 5 PM.
During the weekend, we can see that ride distributions change for both casual and registered users. Still registered rides are more frequendt than casual ones, but both distributions have the same shape, almost uniformily distributed between the time interval of 11 AM to 6 PM.
Seasonal Impact on Rides
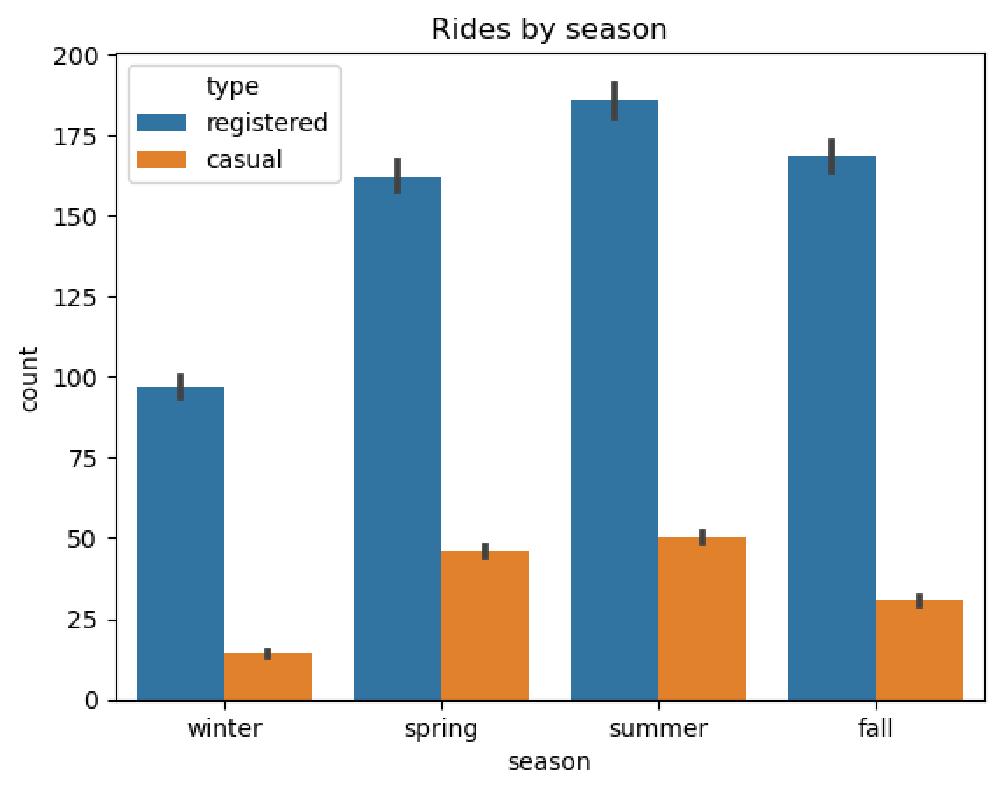
We will investigate the impact of the different seasons on the number of rides per hour.
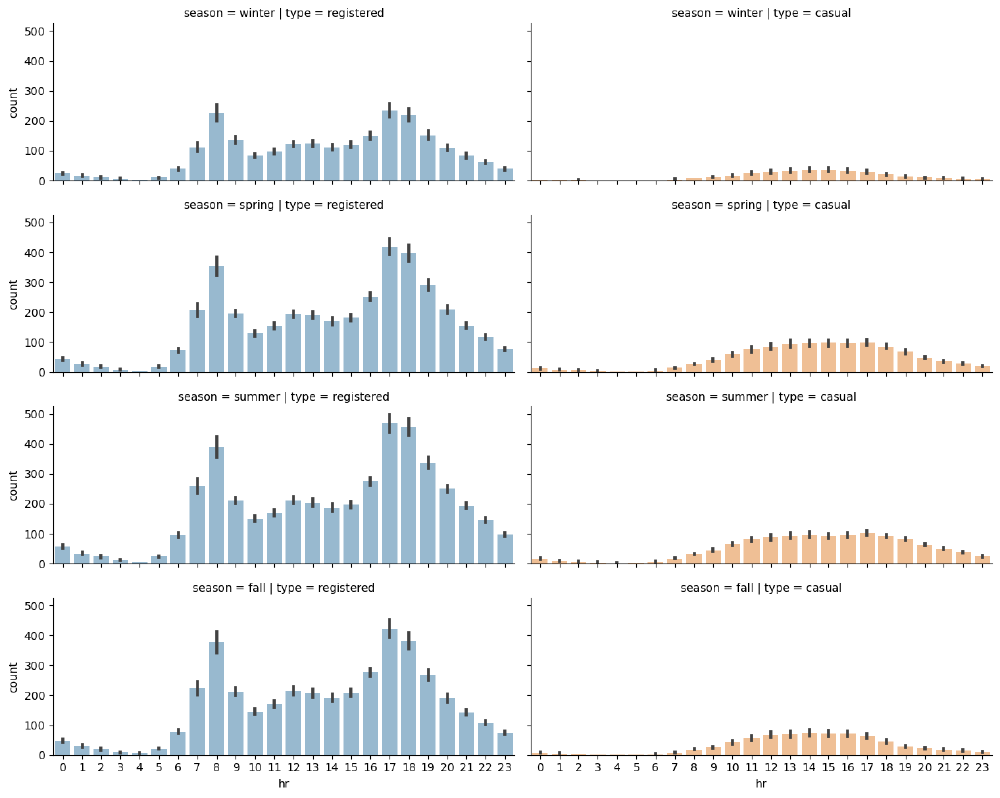
As can be seen in the plot, while each season has a similar graph shape, the count is lower for the winter graph as we can see in the following chart. So there are fewer rides (registered and casual) during winter.
| |
C:\Users\Glenn Pascal M\anaconda3\Lib\site-packages\seaborn\axisgrid.py:118: UserWarning: The figure layout has changed to tight
self._figure.tight_layout(*args, **kwargs)
<seaborn.axisgrid.FacetGrid at 0x20523f0f010>
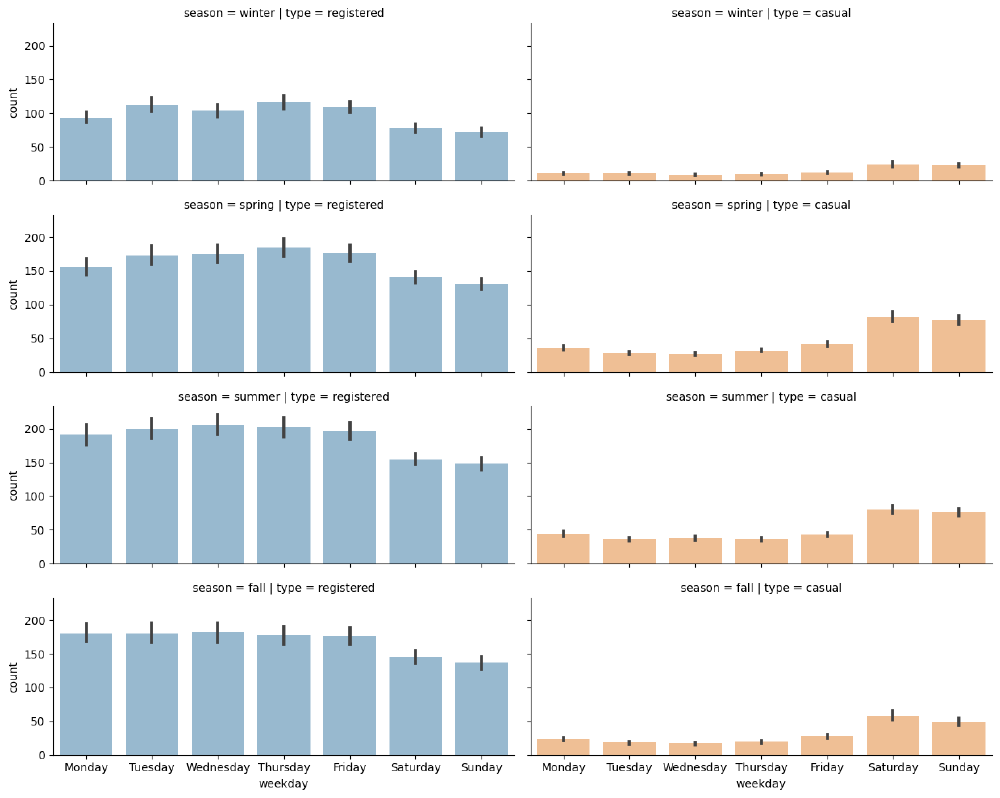
The shape of rides for registered users is nearly uniformilly distributed with a decreasing number of rides over the weekend, while the number of casual rides increases on the weekend.
This could enforce our initial hypothesis, that is, that registered customers mostly use the bike sharing service for commuting (which could be the reason for the decreasing number of registered rides over the weekend), while casual customers use the service occasionally over the weekend.
Of course, such a conclusion cannot be based solely on plot observations but has to be backed by statistical tests, which is the topic of our next section.
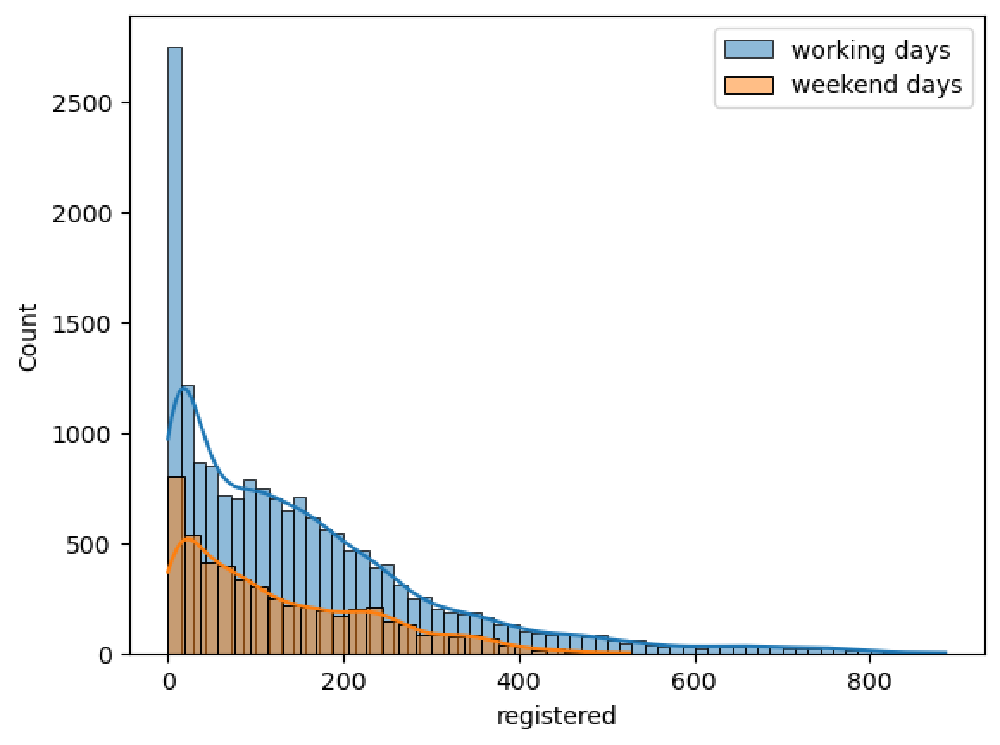
Hypothesis Testing on Registered Rides
In the previous section, we observed, graphically, that registered users tend to perform more rides during working days than the weekend. In order to assess this statement, we will perform a hypothesis test in which we will test whether the mean of registered rides during working days is the same as during the weekend.
Let’s check whether there is a significant difference between registered rides during working days and the weekend.
$H_0$: average registered rides over weekdays - average registered rides over weekend = 0
and
$H_1$: average registered rides over weekdays - average registered rides over weekend $\neq$0
Statistic value:12.522920542969024, p-value:0.000
The resulting p-value from this test is far below the standard critical 0.05 value. As a conclusion, we can reject the null hypothesis and confirm that our initial observation is correct: that is, there is a statistically significant difference between the number of rides performed during working days and the weekend.
Hypothesis Testing on Casual Rides
Let’s check whether there is a significant difference between casual rides during the weekend and working days.
$H_0$: average casual rides over weekend - average casual rides over weekdays = 0
and
$H_1$: average casual rides over weekdays - average casual rides over weekend $\neq$0
| |
| |
Statistic value:25.927301629969712, p-value:0.000
The resulting p-value from this test is far below the standard critical 0.05 value. As a conclusion, we can reject the null hypothesis and confirm that our initial observation is correct: that is, there is a statistically significant difference between the number of rides performed during working days and the weekend.
| |
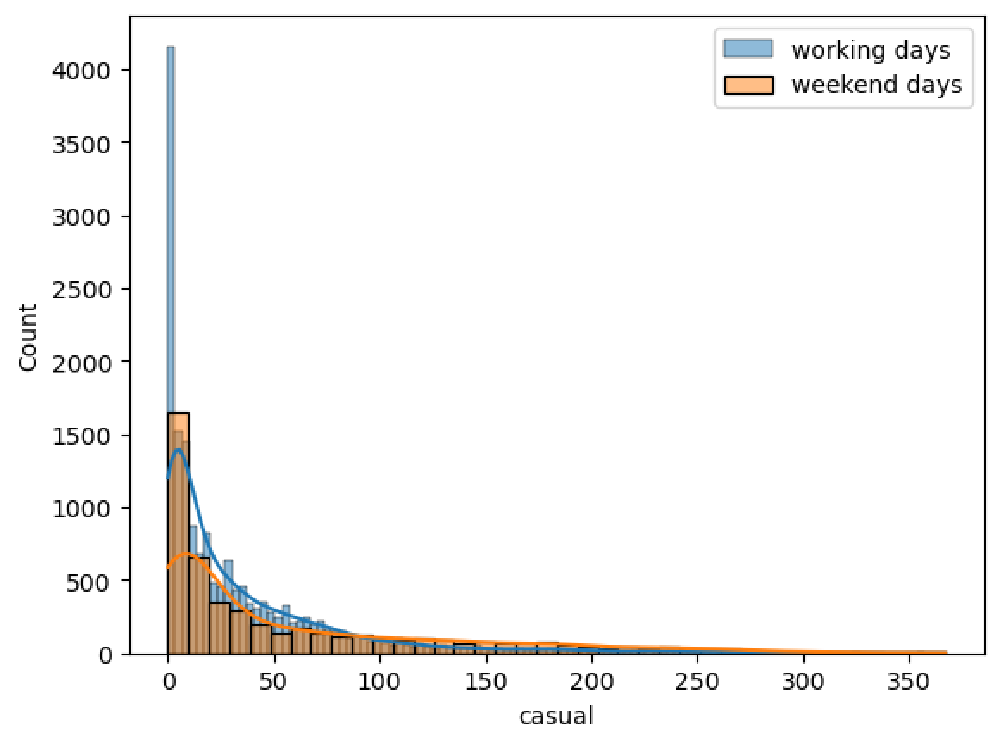
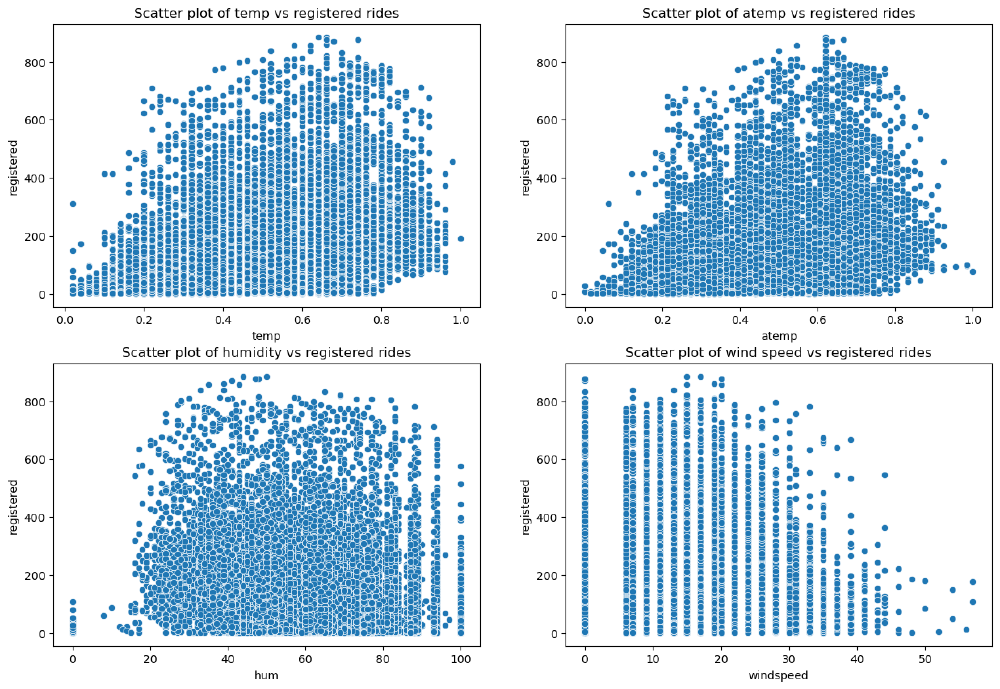
Analysis of Weather-Related Features
The weather features we identified earlier are the following:
• weathersit: This is a categorical variable representing the current weather situation.
• temp: This is the normalized temperature in Celsius. Values are divided by 41, which means that the highest registered temperature in the data is 41°C (corresponding to 1 in our dataset).
• atemp: The normalized feeling temperature in Celsius. Values are divided by 50, which means that the highest registered temperature in the data is 50°C (corresponding to 1 in our dataset).
• hum: The humidity level as a percentage.
• windspeed: The wind speed in m/s.
| |
| |
| |
Text(0.5, 1.0, 'Correlation Matrix Plot')
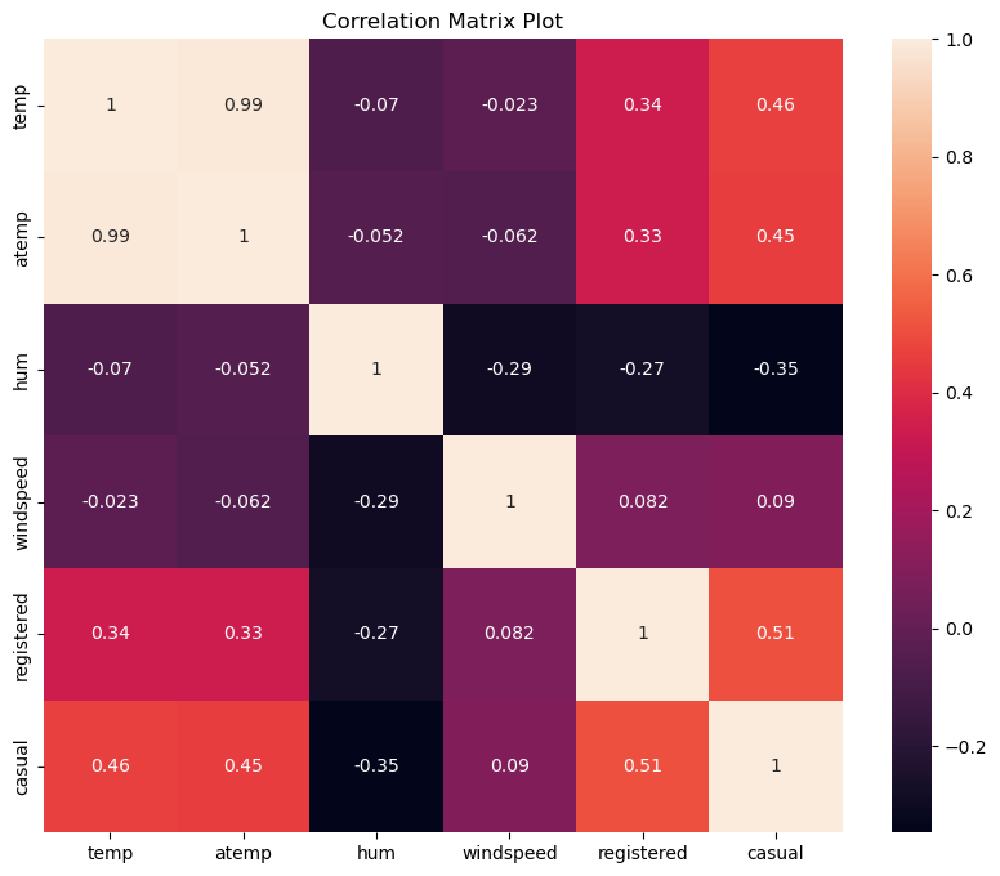
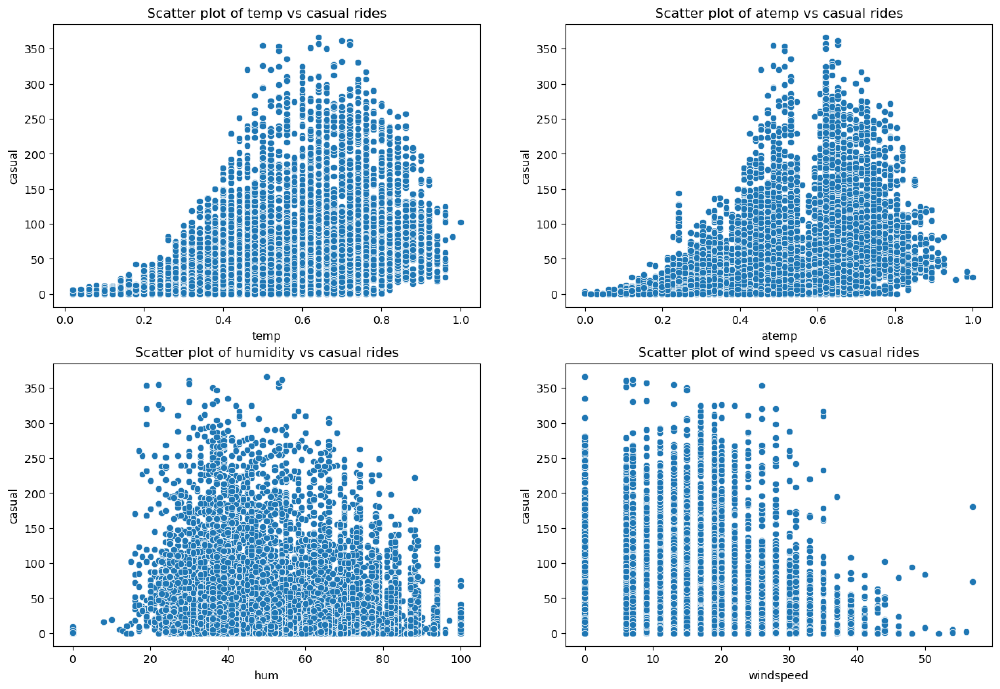
An interpretation of this result is that casual customers are far keener on using the bike sharing service when temperatures are higher. We have already seen from our previous analysis that casual customers ride mostly during the weekend, and they do not rely on bike sharing services for commuting to work. This conclusion is again confirmed by the strong relationship with temperature, as opposed to registered customers, whose rides have a weaker correlation with temperature.
Time Series Analysis
In this section, we perform a time series analysis on the rides columns registered and casual in the bike sharing dataset.
We will use the rolling statistics and the Augmented Dickey-Fuller stationary test to check whether the time series for both registered and casual rides are stationary.
| |
| |
| |
<Figure size 640x480 with 0 Axes>
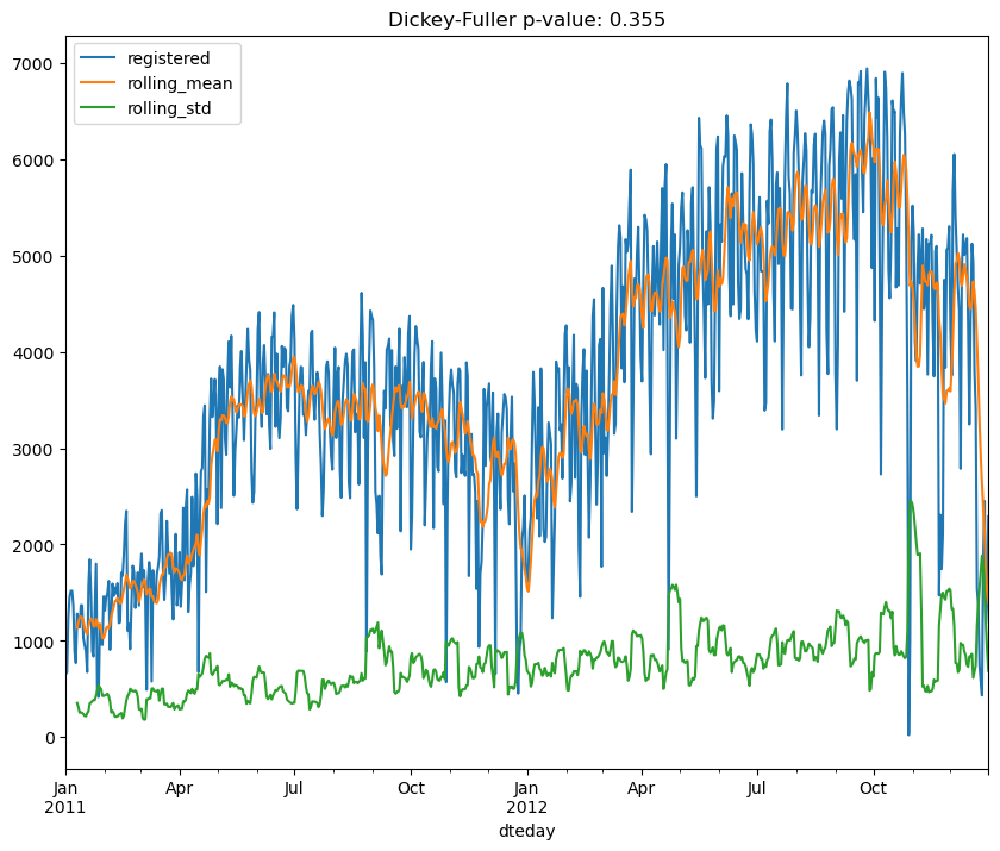
| |
<Figure size 640x480 with 0 Axes>
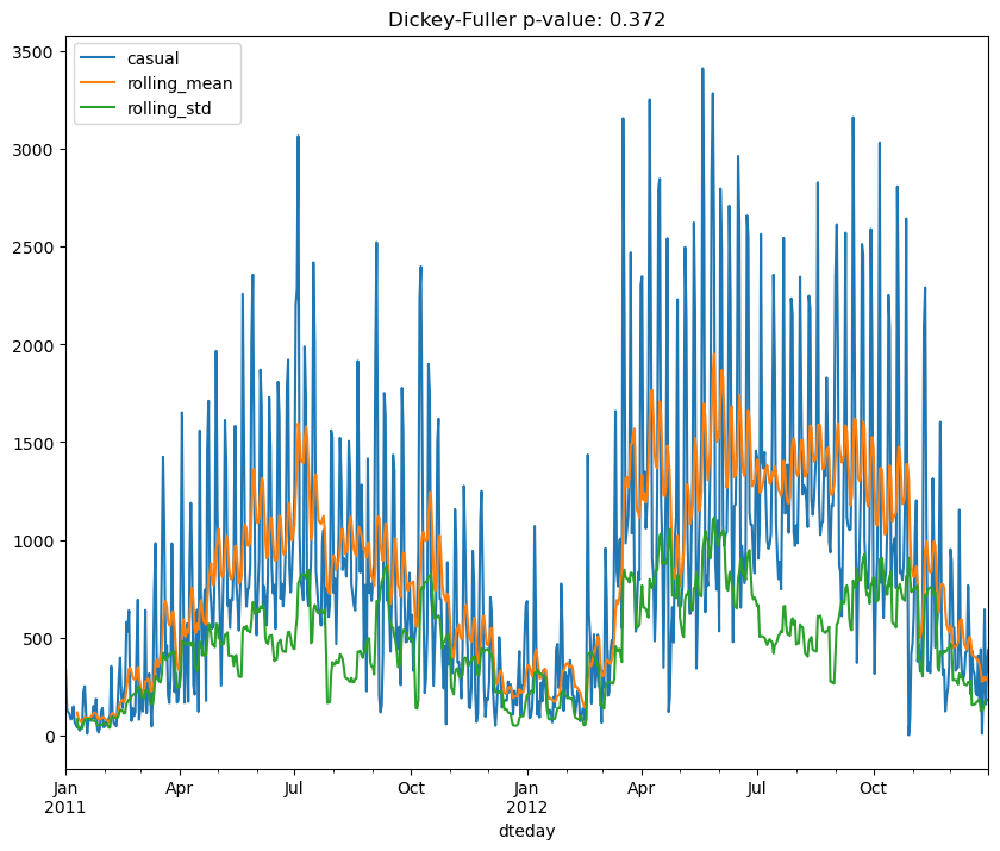
From the performed tests, we can see that neither the moving average nor standard deviations are stationary. Furthermore, the Dickey-Fuller test returns values of 0.355 and 0.372 for the registered and casual columns, respectively. This is strong evidence that the time series is not stationary, and we need to process them in order to obtain a stationary one.
| |